

The CRISCO-HT website gives access to syntactically annotated linguistic corpora produced by the
team of researchers and research engineers at the CRISCO lab, University of Caen, Normandy. The
site
allows searching the annotated corpora (Search tab)
and
gives access to digitised texts (Corpus tab).
DISCLAIMER: Please note that the texts have been annotated using a semi-automated annotation workflow and some
errors, most importantly where syntactic functions are concerned, may still remain. If you have
any
feedback or comments, please do not hesitate to contact the team via the email listed in the Corpus tab.
The corpora presented on this website are also available via the CRISCO lab TXM portal,
maintained
by Humanum.
To access digitised texts, please select the Corpus tab and choose the corpus you are interested in from the left-hand menu. The list of texts of the corpus provides links to the texts free from copyright restrictions (column Text) and, wherever available, links to reproductions of the editions (Original). When reading a text, a menu on the left-hand side gives you the possibility to access other texts of the same corpus.
The corpora can be searched using the Search. It includes several functionalities.
“Corpus selection”: located in a grey box on the top left-hand side of the screen, this
functionality allows you to choose the texts that you want to search. You can select all the
texts (through the default “Select all” option), or only some of them (by unchecking “Select
all" and checking the relevant text(s)).

“Simple Request”: located in the green central box, this functionality allows you to
formulate a
“simple” query (i.e. a query concerning a single word - “pivot” - in context) on the
selected
corpus. The three buttons − “Word”, “Part of speech selection”, and “Function selection” −
can
be used individually or in conjunction.

The “Word” button offers the possibility to search by “word form” or “lemma” .
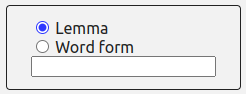
- By checking “Word form”, you are requesting only the form that you are typing. Thus,
searching
for “parti” will not return any other orthographic or otherwise inflected item.

- By checking “Lemma”, all the orthographic and grammatical forms of the item that you are
typing will be returned, taking into account grammatical and spelling variation present in
the
selected corpus.

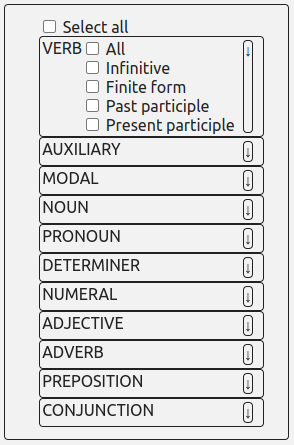
The “Part of speech selection” button allows “advanced” search; you can thus choose the
grammatical class of the required form or lemma, or all the forms of the relevant class if
you
do not enter a specific form. Several grammatical classes are listed: verb, auxiliary,
modal,
noun, pronoun, determinant, numeral, adjective, adverb, preposition, conjunction. To further
refine your search, it is possible to display sub-categories within each grammatical class
by
clicking on the arrow “↓” located to the right of the box.
The “Function selection” button allows you to select the desired grammatical function for the chosen form, or all the items that have the selected function if you do not enter a specific form. Currently, subject, direct object, indirect object (personal pronouns only) and oblique functions are available.
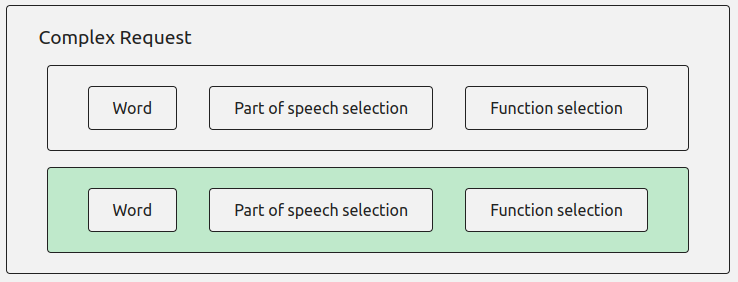
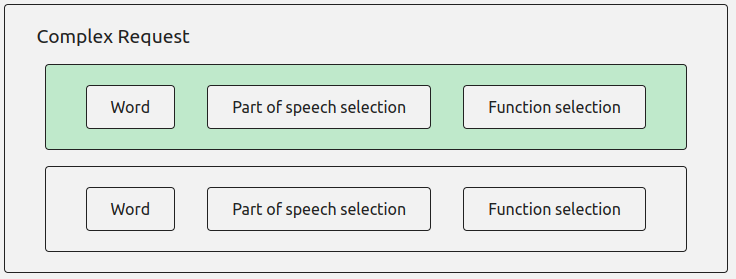
The “Collocation” button opens up a wider range of parameters to perform a “Complex
Request”:

The “Complex Request” allows you to associate another item with the first, by selecting
the
same options. You can also choose whether the second item should follow (“After”) or
precede
(“Before”) the first.
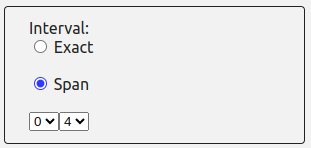
The distance between the items. The “Interval” box allows you to select the number of
words
you want to find between the two searched items.
- By checking “Exact” and using the counter, you can select the exact interval from 0 to
9
words.

- By checking “Span” and using the counters, you can select a span between 0 and 9 words
between the first and second item. Collocations occurring at a distance between the
chosen
figures will also be returned by the search.
- Just below, the “Exclude punctuation from interval:” box allows you to choose whether
or
not to exclude punctuation from the interval. If you choose the default option to
exclude
punctuation from the interval, only items appearing between two punctuation signs
(comma,
colon, semi-colon) will be included in the search, otherwise items separated by
punctuation
will also be displayed.

-The length of the displayed extract is defined using the “Context selection” button.

- Check “Full sentence” to display the complete sentence in which the searched item is
found.
- Check “10 words” to display the 10 words before and after the searched item.
[10 words - pivot - 10 words]
- Check “20 words” to display the 20 words before and after the searched item.
[20 words - pivot - 20 words]
Texts subject to copyright will display a maximum of 20 words.
Please note that even in the case of the latter two options the limits of the sentence will
not
be exceeded when the contexts are displayed.
Once all the parameters have been defined, the “Search” button allows you to launch the
search.
Once the search has been performed, a list of occurrences appears below the request
parameters
buttons. A table summarising the search parameters is also displayed.
If you would like to modify the parameters for a next search, you can do so by altering your
selection in the drop-down menus of the “Word”, “Part of Speech Selection” and “Function
Selection” buttons according to new search criteria.
You can download the search results in a tabular format by clicking the Export to TSV button
in
the top right corner of the results box.
By clicking on the underlined search results in the results box, a new browser tab will open that will take you to the relevant sentence in the text. Please note that this is only possible for texts of the corpus that do not have copyright restrictions.
In the top right corner of the screen, the "Clear session" box allows you to reset the
search.
It automatically clears all previously selected parameters. Without resetting the session,
the
search will be performed on the basis of the previous query.
![]()
The annotation was carried out using the semi-automated annotation workflow. For all corpora presented here,annotation and lemmatisation were carried out using the semi-automated workflow developed as part of the High-Tech corpus. The Part of Speech tagging that supports the search options presented on this website, was implemented following three annotation systems: Universal Dependencies, UPenn and Presto. To know more about the PoS annotation programme, please refer to the documentation pages on the CRISCO lab’s TXM portal. Syntactic function analysis was done automatically using HOPS parser, according to Universal Dependencies conventions.
Blumenthal, P., Diwersy, S., Falaise, A., Lay, H., Souvay, G., Vigier, D., Descartes, P. R.,
Nancy, U., & de Lyon, U. (2017). Presto, un corpus diachronique pour le français des
XVIe-XXe siècles.
de Marneffe, M.-C., Manning, C. D., Nivre, J., & Zeman, D. (2021). Universal Dependencies.
Computational Linguistics, 47(2), 255-308. https://doi.org/10.1162/coli_a_00402
DeRose, S. (1999). XML and the TEI. Computers and the Humanities, 33(1), 11-30.
https://doi.org/10.1023/A:1001771114509
Goux, M. & Pinzin F. Challenges of a Multilingual Corpus (Old French/Old Venetian): The
Example of the MICLE project. Venise et la France. Similitudes, spécificités,
interrelations. Castro E., Della Fontana A. and Pezzini E. Franco Cesati (ed) Florence :
Cesati Editore (sous presse).
Grobol, L., & Crabbé, B. (2021). Analyse en dépendances du français avec des plongements
contextualisés (French dependency parsing with contextualized embeddings). Actes de la 28e
Conférence sur le Traitement Automatique des Langues Naturelles. Volume 1 : conférence
principale, 106-114. https://aclanthology.org/2021.jeptalnrecital-taln.9
Lay, M.-H. & Pincemin, B. (2010). Pour une exploration humaniste des textes : AnaLog.
Statistical Analysis of Textual Data: Proceedings of 10th International Conference Journée
d’Analyse statistique des Données Textuelles 9-11 Juin 2010 – Sapienza University of Rome.
Bolasco, S., Chiari I. & Giuliano L. (eds) V.2, 1045-1056
https://www.ledonline.it/ledonline/JADT-2010/allegati/JADT-2010-1045-1056_106-Lay.pdf
Miletic A., Fabre C. & Stosic D. (2018). De la constitution d'un corpus arboré à l'analyse
syntaxique du serbe. Revue TAL : traitement automatique des langues,.59 (3). pp.15-39.
⟨hal-02007248⟩
Morcos, H., Noël, G. & Husar, M. Lemmatization in the collaborative editorial workflow of a
medieval French text: The digital edition of the Ancient History jusqu’à César. Digital
Scholarship in the Humanities, 36(2), 203-209. https://doi.org/10.1093/llc/fqaa060
Santorini, B. (2007) Protocole d'étiquetage - Parties du discours (PDD).
https://www.ling.upenn.edu/~beatrice/corpus-ling/annotation-french/pos/pos-index.html
Peng Z., Gerdes K. & Guiller K. (2022). Pull your treebank up by its own bootstraps.
Journées Jointes des Groupements de Recherche Linguistique Informatique, Formelle et de
Terrain (LIFT) et Traitement Automatique des Langues (TAL), Nov 2022, Marseille, France.
pp.139-153. ⟨hal-03846834⟩
Ziane R., Romanova N., Lavergne M. En dialogue avec les outils d'apprentissage automatique:
une chaîne de traitement pour l'annotation syntaxique. Journée d'études CRISCO axe 2, 8 june
2023. Workshop slides
Ziane R., Romanova N. Vers l’intégration des outils d’annotation syntaxique : proposition
d’une chaîne de traitement itérative pour faciliter l’adoption et l’accès aux technologies
d’apprentissage automatique Actes des 11èmes Journées Internationales de Linguistique de
Corpus, 3-7 juillet 2023, pp. 278-383 Conference booklet
Ziane R. Présentation du projet High-Tech. Seminaire du CRISCO, 12 octobre 2023. Recorded
lecture